【学习笔记】 文本分析
网课知识点汇总
NLTK与jieba概述
NLP:自然语言处理
NLTK:是一套基于Python的自然语言处理工具包,可以方便地完成自然语言处理的任务
| 语言处理任务 | nltk模块 | 功能描述 |
|---|---|---|
| 获取和处理语料库 | nltk.corpus | 语料库和词典的标准化接口 |
| 字符串处理 | nltk.tokenize, nltk.stem | 分词,句子分解提取主干 |
| 搭配发现 , | nltk.collocations | 用于识别搭配工具,查找单词之间的关联关系 |
| 词性标识符 | nltk.tag | 包含用于词性标注的类和接口 |
| 分类 | nltk.classify, nltk.cluster | nltk.classify用类别标签标记的接口;nltk.cluster包含了许多聚类算法 如贝叶斯、EM、k-means |
| 分块 | nltk.chunk | 在不受限制的文本识别非重叠语言组的类和接口 |
| 解析 | nltk.parse | 对图表、概率等解析的接口 |
| 语义解释 | nltk.sem, nltk.inference | 阶逻辑,模型检验 |
| 指标评测 | nltk.metrics | 精度,召回率,协议系数 |
| 概率与估计 | nltk.probability | 计算频率分布、平滑概率分布的接 口 |
| 应用 | nltk.app,nltk.chat | 图形化的关键词排序,分析器, WordNet查看器,聊天机器人 |
| 语言学领域的工作 | nltk.toolbox | 处理SIL工具箱格式的数据 |
jieba:中文分词组件,支持以下三种分词模式
1、精确模式:试图将句子最精确地切开,适合文本分析
2、全模式:把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能解决歧义
3、搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
安装NLTK的方法
1 | ##1、在终端使用pip命令直接安装: |
jieba库的安装
1 | ##如果希望对中文进行分词操作,则需要借助 jieba分词工具完成。安装jieba库的方式比较简单,可以使用如下pip命令直接安装: |
文本预处理
文本预处理一般包括分词、词形归一化、删除停用词,具体流程如下所示:
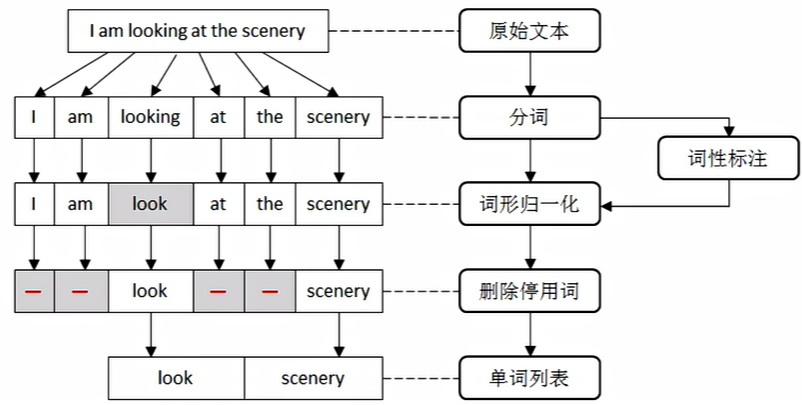
分词
分词是指将由连续字符组成的语句,按照一定的规则划分成一个个独立词语的过程。
不同的语言具有不同的语法结构。英文以空格为分隔符,中文没有形式上的分隔符。
根据中文的结构特点,可以把分词算法分为以下三类:
1、基于规则的分词方法:按照一定的策略将待分析的中文句子与一个“充分大的”机器词典中的词条进行匹配。
2、基于统计的分词方法:它的基本思想是常用的词语是比较稳定的组合。
3、基于理解的分词方法:它的基本思想是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。
要想使用NLTK对英文句子分词,则可以调用word_tokenize()函数基于空格或标点进行划分,并返回单词列表。
1 | sentence = 'I like bule.' |
要想使用jieba对中文句子分词,则可以通过jieba.cut()函数进行划分,该函数接收如下三个参数:
1、需要分词的字符串。
2、cut_all参数用来控制是否采用全模式。设置为True则为全模式,False为精确模式,默认为False。
3、HMM参数用来控制是否使用HMM模型。
1 | #全模式True |
词性表注
词性是对词语分类的一种方式。
英文词汇:名词、形容词、动词、代词、数词、副词、介词、连词、冠词和感叹词。
中文词汇:名词、动词、形容词、数词、量词、代词、介词副词、连词、感叹词、助词和拟声词。
词性标注,又称词类标注,是指为分词结果中的每个词标注一个正确的词性。
1 | ##I love itcast |
NLTK库中使用不同的约定来标记单词
| 标签 | 描述 | 示例 |
|---|---|---|
| JJ | 形容词 | special, high, good |
| RB | 副词 | quickly, simply, hardly |
| CC | 条件连词 | and, or |
| DT | 限定词 | the,a |
| MD | 情态动词 | could, should |
| NN | 单数名词 | home, time, year |
| NNS | 复数名词 | birds, dogs, flowers |
| NNP | 专有名词单数 | Affica, April, Washington |
| CD | 基本数量词 | twenty-one, second, 1997 |
| PRP | 人称代词 | I, you, he, she |
| PRPS | 所有格代词 | my, your, his, her |
| IN | 介词 | on,of, at,by,under |
| TO | 不定词 | howto,whattodo |
| UH | 感叹词 | ah,ha,wow, oh |
| VB | 动词原型 | see,listen, speak, run |
| VBD | 动词过去时 | did, told, made |
| VBG | 动名词 | going,working,making |
| VBN | 动词过去分词 | given, taken, begun |
| WDT | WH限定词 | which,whatever |
如果希望给单词标注词性,则需要先确保已经下载了averaged_perceptron_tagger模块,然后再调用pos_tag()函数进行标注。
1 | words = nltk.word_tokenize('I love blue') |
词形归一化
在英文中,一个单词常常是另一个单词的变种。一般在信息检索和文本挖据时,需要对一个词的不同形态进行规范化,以提高文本处理的效率。
词形还原是去除词缀以获得单词的基本形式。这个基本形式称为根词,而不是词干。根词始终存在于词典中,词干不一定是标准的单词,它可能不存在于词典中。
词根:look 一般进行时:looking 一般过去时:looked
词形规范化过程主要包括两种:词干提取和词形还原。
词干提取:是指删除不影响词性的词缀,得到单词词干的过程
词形还原:能够捕捉基于词根的规范单词形式
1、目前最受欢迎的就是波特词干提取器,它是基于波特词干算法来提取词干的,这些算法都集中在PorterStemmer类中。
1 | from nltk.stem.porter import PorterStemmer |
2、还可以用兰卡斯特词干提取器,它是基于兰卡斯特词干算法来提取词干的,这些算法都集中在LancasterStemmer类中。
1 | from nltk.stem.lancaster import LancasterStemmer |
3、还有一些其它的词干器,比如 SnowballStemmer,它除了支持英文以外,还支持其它13种不同的语言。
1 | from nltk.stem import SnowballStemmer |
4、NLTK库中提供了一个强大的还原模块,它使用WordNetLemmatizer类来获得根词,使用前需要确保已经下载了wordnet语料库。lemmatize()方法会比对wordnet语料库,并采用递归技术删除词缀,直至在词汇网络中找到匹配项,最终返回输入词的基本形式。如果没有找到匹配项,则直接返回输入词,不做任何变化。
1 | #导入模块 |
删除停用词
停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言文本之前或之后会自动过滤掉某些没有具体意义的字或词。比如英文中的I、the,中文中的啊。
如果直接用包含大量停用词的文本作为分析对象,则可能会导致分析结果存在较大偏差通常在处理过程中会将它们从文本中删除。
停用词都是人工输入、非自动化生成的,生成后的停用词会形成一个停用词表,但是并没有一个明确的停用词表能够适用于所有的工具。
对于中文的停用词,可以参考中文停用词库、哈工大停用词表、百度停用词列表。对于其它语言来说,可以参照 https://www.ranks.nl/stopwords进行了解。
NLTK库里面有一个标准的停用词列表,在使用之前要确保已经下载了stopwords语料库,并且用import语句导入stopwords模块。
1 | ##下载语料库 |
文本情感分析
文本情感分析,又称为倾向性分析和意见挖掘是指对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。
情感分析还可以细分为情感极性(倾向)分析、情感程度分析及主客观分析等。其中,情感极性分析的目的在于,对文本进行褒义、贬义、中性的判断,比如对于“喜爱”和“厌恶”这两个词,就属于不同的情感倾向。
目前,常见的情感极性分析方法主要分为两种:基于情感词典和基于机器学习。
情感词典:是最简单的情感极性分析的方式,通过制定一系列的情感词典和规则,对文本进行段落拆解句法分析,计算情感值,最后通过情感值来作为文本的情感倾向依据。使用情感词典的方式虽然简单粗暴,但是非常实用,不过一旦遇到一些新词或者特殊词,就无法识别出来,扩展性非常不好。
第一步:对文本进行分词操作,从中找出情感词、否定词以及程度副词。
第二步:判断每个情感词之前是否有否定词及程度副词,将它之前的否定词和程度副词划分为一组。
第三步:将所有组的得分加起来,得分大于0的归于正向,小于0的归于负向。
机器学习:将目标情感分为两类:正、负或者是根据不同的情感程度划分为15类,然后对训练文本进行人工标注,进行有监督的机器学习过程。其中,朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法。朴素贝叶斯的思想基础是:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。nltk.classify模块中的NaiveBayesClassifier类实现了朴素贝叶斯分类算法,该类中有一个类方法 train(),主要用于根据训练集来训练模型。
1 | #准备用于训练的文本 |
文本相似度
文本映射到向量,再利用余弦相似度计算的一般实现步骤如下:
第一步:通过特征提取的模型或手动实现,找出这两篇文章的关键词。
第二步:从每篇文章中各取出若干个关键词,再把这些关键词合并成一个集合,然后计算每篇文章中各个词对于这个集合中的关键词的词频。
第三步:生成两篇文章中各自的词频向量。
第四步:计算两个向量的余弦相似度,值越大侧表示越相似。
1 | #导入模块 |
参考来源
作话:不属于0基础,还是要先了解基本的python代码
